Fault Tolerance Strategy
Dubbo offers a variety of fault-tolerant scenarios when a cluster call fails, with a default failover retry.
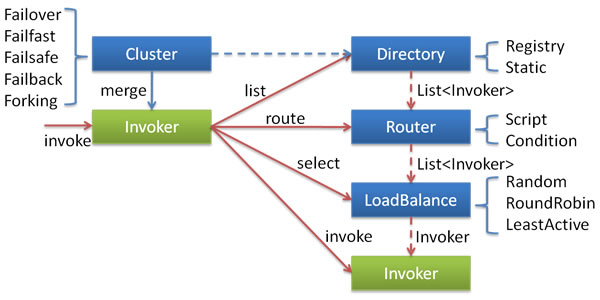
The relationship between nodes:
- This
Invokeris the callable Service’s abstract of theProvider, and theInvokerpackaging theProvider’s address andService’s interface. - The
Directoryrepresent multipleInvoker,You can think of it asList<Invoker>,But unlikeList,its value can be dynamically changing.such as registry push changes - The
Clusterdisguises multipleInvokerinDirectoryas aInvoker,The upper transparent, masquerade process contains fault-tolerant logic, call failed, try another - The
Routeris responsible for selecting subsets according to routing rules from multipleInvokers, such as read-write separation, application isolation, etc. LoadBalanceis responsible for selecting a specific one from multipleInvokerfor this call. The selection process includes the load balancing algorithm. If the call fails, it needs to be re-selected
Cluster fault-tolerant mode
You can also customize the cluster fault tolerance strategy, see Cluster extension for more details.
Failover Cluster
Failure automatically switch, when there is failure, retry the other server (default). Usually used for read operations, but retries can result in longer delays. The times of retries can be set via retries =2 (excluding the first time).
The times of retries is configured as follows:
<dubbo:service retries="2" />
OR
<dubbo:reference retries="2" />
OR
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference>
Failfast Cluster
Fast failure, only made a call, failure immediately error. Usually used for non-idempotent write operations, such as adding records
Failsafe Cluster
Failure of security, anomalies, directly ignored. Usually used to write audit logs and other operations.
Failback Cluster
Failure automatically restored, failed to record the background request, regular retransmission. Usually used for message notification operations.
Forking Cluster
Multiple servers are invoked in parallel, returning as soon as one succeeds. Usually used for real-time demanding read operations, but need to waste more service resources. The maximum number of parallelism can be set with forks=2.
Broadcast Cluster
Calling all providers broadcast, one by one call, any error is reported (2.1.0+). It is usually used to notify all providers to update local resource information such as caches or logs.
Now in the broadcast call, the proportion of node call failures can be configured through broadcast.fail.percent. When this proportion is reached, BroadcastClusterInvoker will no longer call other nodes and directly throw an exception. The value of broadcast.fail.percent is in the range of 0-100. By default, an exception will be thrown when all calls fail. broadcast.fail.percent only controls whether to continue to call other nodes after failure, and does not change the result (any one will report an error). broadcast.fail.percent parameters Effective in dubbo2.7.10 and above.
Broadcast Cluster configuration broadcast.fail.percent.
broadcast.fail.percent=20 means that when 20% of the nodes fail to call, an exception will be thrown and no other nodes will be called.
@reference(cluster = "broadcast", parameters = {"broadcast.fail.percent", "20"})
Cluster mode configuration
Follow the example below to configure cluster mode on service providers and consumers
<dubbo:service cluster="failsafe" />
OR
<dubbo:reference cluster="failsafe" />